
Tempo de leitura: 21 minutos
Muitas organizações exigem que membros de equipes de projeto forneçam atualizações regulares do status do projeto como parte do processo de monitoramento do projeto.
Essas atualizações geralmente consistem em comentários de texto associados a um status vermelho-âmbar-verde (RAG), em que vermelho indica um projeto/tarefa com falha, âmbar uma tarefa/projeto em risco e verde uma tarefa/projeto em andamento conforme planejado.
Este trabalho propõe o desenvolvimento de um modelo de aprendizado de máquina, com apoio de NLP e Redes Neurais, para priorizar tarefas através de algoritmos de classificação de nível de riscos de acordo com marcadores RAG.
Objetivo do Case
Este projeto tem como objetivo utilizar uma combinação de APIs REST, processamento de linguagem natural (NLP) e Redes Neurais para prever o sentimento de risco em tarefas de projetos e possibilitar que os gerentes de projeto sejam notificados de forma proativa sobre possíveis impactos no projeto.
Vamos realizar a classificação usando a abordagem de tokenização, representação vetorial e análise estatística juntamente com a abordagem de aprendizado de máquina por transferência, comparando o resultado de ambas.
Para alcançar esse objetivo, o projeto se inspira no processo de classificação de mensagens definido pela Oracle em seu software PPM. A base de dados a ser utilizada consiste em comentários de tarefas registrados no software PPM NetProject.
Como resultados esperados, pretendemos integrar a API REST desenvolvida neste trabalho ao software de gestão de projetos e portfólio NetProject. Assim, será possível definir previamente um farol de Status em Verde, Amarelo ou Vermelho, conforme magem abaixo:
Projetos e Gestão de Projetos
Os projetos são os meios pelos quais as empresas implementam suas estratégias, o que significa que são um componente crucial do sucesso empresarial.
A gestão de projetos recebeu destaque nos últimos anos devido a uma combinação de fatores que têm impulsionado sua importância e relevância em diversos setores e organizações. Dentre estes fatores podemos citar a complexidade dos projetos, a competitividade do mercado, o forco em resultados e a necessidade de inovação.
Apesar do uso de ferramentas de controle e monitoramento de projetos, as taxas de sucesso do projeto ainda são muito baixas. Isso é motivo de preocupação, pois tem um impacto econômico significativo nas empresas e indústrias como um todo.
Captura do progresso de tarefas
Os gerentes de projeto devem capturar o progresso da tarefa dos membros da equipe para prever com precisão os impactos no cronograma do projeto e comunicar o progresso e os riscos ao gerenciamento. Os gerentes, com este processo, buscam identificar status da tarefa e quaisquer impactos no cronograma do projeto. Por exemplo, quando um membro da equipe sabe que uma tarefa será adiada, ele deve comunicar isso ao gerente do projeto. Se não o fizer, o gerente do projeto permanecerá inconsciente dos impactos no cronograma do projeto.
Os gerentes de projeto podem conversar com os membros da equipe usando módulos de mensagem presentes em ferramentas de gerenciamento de portfólio de projetos, ou Portfólio and Project Management (PPM).
O PPM é uma ferramenta que desempenha um papel fundamental na coleta de informações dos níveis operacionais e sua consolidação no nível do portfólio para a tomada de decisões estratégicas.
Status Vermelho-âmbar-verde (RAG)
Muitas organizações exigem que os gerentes de projeto façam atualizações regulares do status do projeto como parte do processo de monitoramento do projeto.
Essas atualizações geralmente consistem em comentários de texto associados a um status vermelho-âmbar-verde (RAG), onde vermelho indica um projeto/tarefa com falha, âmbar uma tarefa/projeto em risco, verde uma tarefa/projeto em andamento.
Ao automatizar esse processo, o gerente poderia focar seu trabalho de acompanhamento periódico apenas nas tarefas destacadas com maior chance de problemas, ou seja, as que possuírem maior pontuação no ranking proposto neste trabalho.
O rankeamento proposto permite que gerentes de projeto dediquem mais tempo na comunicação efetiva com a equipe. Importante ressaltar que as competências dos gerentes de projeto em aspectos de comunicação contribuem significativamente para a satisfação e produtividade dos membros da equipe, consequentemente para o sucesso do projeto.
Processamento de Linguagens Naturais
O Processamento de Linguagem Natural, ou Natural Language Processing (NLP) é uma área interdisciplinar que envolve habilidades computacionais, humanísticas e estatísticas-matemáticas. O objetivo do NLP é capacitar os computadores a entender, interpretar e interagir com a linguagem humana de forma natural.
O objetivo é permitir que as máquinas compreendam textos escritos ou falados, gerem respostas coerentes, traduzam idiomas, extraiam informações úteis e realizem tarefas relacionadas à linguagem, como análise de sentimentos e correção ortográfica, entre outras aplicações.
A linguagem humana pode ser definida como natural porque é ambígua e mutável. Por outro lado, a linguagem de máquina é definida como formal porque é inequívoca e reconhecida internacionalmente. O NLP deve lidar de forma otimizada com a ambiguidade, imprecisão e falta de dados inerentes à linguagem natural.
Inteligência Artificial e Redes Neurais Artificiais
Inteligência Artificial pode ser descrita como a habilidade de uma máquina para reproduzir o comportamento da inteligência humana, buscando utilizar algoritmos para resolução aproximada de problemas desafiadores.
Os principais subgrupos da IA são: o Reconhecimento de Padrões, o Aprendizado de Máquina e o Aprendizado Profundo.
Neste trabalho vamos utilizar o Reconhecimento de Padrões e o Aprendizado de Máquina para estabelecer ranking de tarefas e projetos usando o status RAG (Red, Amber, Green).
A IA tem sido usada para avançar em diferentes campos, como educação, saúde, e finanças. No entanto, a aplicação da IA campo do gerenciamento de projetos (GP) não tem progredido igualmente.
As redes neurais artificial são um tipo de inteligência artificial que, até certo ponto, tentam, simular o pensamento humano. Elas são usados para vários fins, como aprovação de crédito, detecção de fraudes, sistemas de vigilância e fins de previsão. Um dos principais componentes das redes neurais é o treinamento, que as ajuda a se ajustar aos padrões de dados e fornecer melhores resultados.
Durante o treinamento, os resultados da rede neural são comparados com dados reais e conhecidos, e o processo é repetido até que a taxa de erro seja muito baixa.
As redes neurais são mais precisas do que os modelos lineares baseados em modelos de regressão, que têm sido frequentemente usados no gerenciamento de projetos. As redes neurais podem lidar com relacionamentos complexos e não lineares entre variáveis.
Portanto, as redes neurais podem ser uma ferramenta útil para a classificação de status de projetos e tarefas a partir de textos, pois podem fornecer previsões e insights mais precisos.
Desenvolvendo o Modelo de Classificação com Representação Vetorial
Nesta etapa do trabalho, utilizamos o conjunto de dados de situação de tarefas para implementar classificadores a partir de representação vetorial TF-IDF.
Carga da Base de Dados e Validação de Carga
A base de dados para este trabalho foi composta por comentários realizados sobre a situação de tarefas juntamente de indicadores RAG (Red, Âmber, Green) que indicam a situação da tarefa em determinado momento do projeto.
A Amostra de comentários e situação em projetos realizados nos últimos 5 antos foram extraídas do software NetProject.
Para enriquecimento desta base foram adicionados os comentários e situações trabalhados no artigo da Oracle.
Número de amostras: 1974
Número de comentários marcados como GREEN: 347
Número de comentários marcados como RED: 907
Número de comentários marcados como AMBER: 720
Preparação dos dados
Os dados textuais brutos acima coletados são pré-processados para transformá-los em um formato adequado para uso nos algoritmos de NLP e Redes Neurais deste artigo. Incluímos a normalização a tokenização, remoção de stop words (palavras muito comuns que não agregam valor para a classificação), lematização ou stemming (redução de palavras à sua forma básica) para prosseguirmos com a vetorização.
Normalização
Para a normalização foi utilizada a biblioteca Enelvo. A biblioteca Enelvo apoia diversas tarefas de Processamento de Linguagem Natural em português porque possui a capacidade de normalizar textos, ou seja, corrige abreviações, gírias, erros ortográficos, capitaliza letras no começo das frases, de nomes próprios e acrônimos. Ela também possui uma função própria para remover pontuações e emojis.
Tokenização e Lematização
Para a tarefas de tokenização e lematização foi utilizada a biblioteca spaCy. A biblioteca spaCy é uma biblioteca de processamento de linguagem natural (NLP) para a linguagem de programação Python, projetada para ser rápida, eficiente e fácil de usar, tornando-se uma das escolhas populares para tarefas de NLP em Python.
Para a biblioteca spaCy conseguir realizar suas funções, é necessário que um modelo de linguagem esteja presente. Optamos pelo modelo “pt core news sm“.
Este é um modelo de linguagem pré-treinado específico para a língua portuguesa, que foi treinado com uma quantidade significativa de texto em português e contém informações sobre tokens, análise sintática, reconhecimento de entidades nomeadas e outras informações linguísticas úteis.
O sufixo “sm” no nome do modelo significa “small” (pequeno), indicando que este é um modelo menor, com menos parâmetros e, portanto, ocupa menos espaço em memória e é mais rápido para carregar e processar em comparação com modelos maiores.
Ao utilizar o modelo “pt core news sm” no spaCy, pode-se fazer análises linguísticas em textos em português, incluindo tokenização, lematização, identificação de entidades nomeadas, análise de dependência sintática e muito mais. Esse modelo pré-treinado economiza tempo e recursos, permitindo focar mais nas tarefas específicas de processamento de linguagem natural para o idioma português.
Remoção de Stop Words
A remoção de stop words em português foi utilizada com apoio da biblioteca NLTK. As stop words são palavras que aparecem com frequência em um idioma, mas geralmente não contribuem significativamente para o significado do texto, como artigos, preposições e pronomes. A remoção dessas palavras pode ajudar a reduzir a dimensionalidade dos dados e melhorar o desempenho de certas tarefas de análise de texto, como a classificação proposta nesse trabalho.
Vetorização
Para vetorização utilizamos a biblioteca TfidfVectorizer, que faz parte do módulo scikit-learn (sklearn). O TfidfVectorizer e é uma ferramenta importante para pré-processamento de texto e vetorização de documentos com base na frequência dos termos em um corpus. A ferramenta calcula a importância relativa de cada palavra em um conjunto de documentos usando a métrica TF-IDF (Term Frequency-Inverse Document Frequency). Essa métrica é frequentemente usada para representar textos em formato numérico, que podem ser usados como entrada para algoritmos de aprendizado de máquina.
Abordagens de Classificação e Resultados
Percebe-se um crescente interesse na categorização de documentos de texto em classificações predefinidas, impulsionado pelo aumento de documentos em formato digital e a necessidade de organizá-los de forma eficiente.
A categorização de texto é amplamente empregada em aplicações de processamento de linguagem natural (NLP), as quais têm obtido êxito por meio da utilização de algoritmos de aprendizado de máquina. No entanto, a classificação de texto ainda representa um desafio para os pesquisadores, que estão em busca da melhor estrutura e técnica adequada para alcançar resultados satisfatórios.
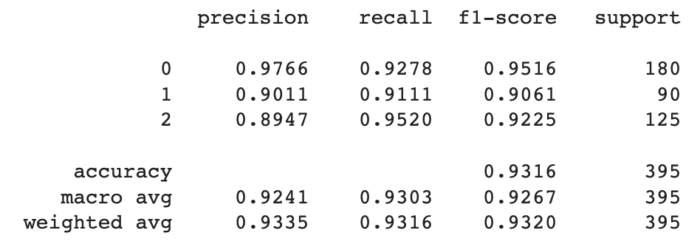
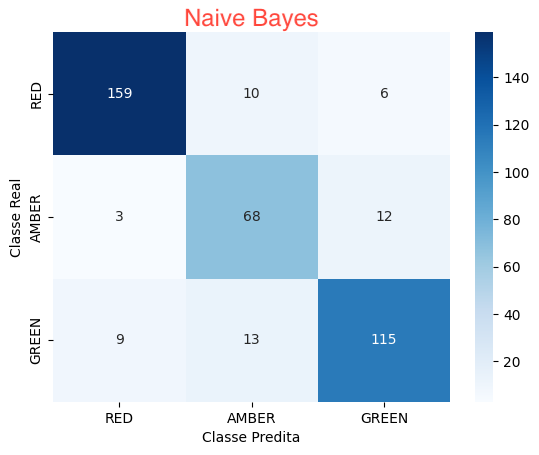
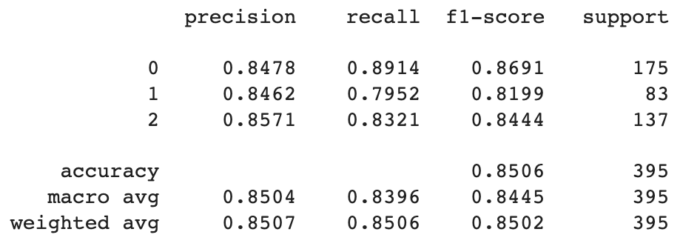
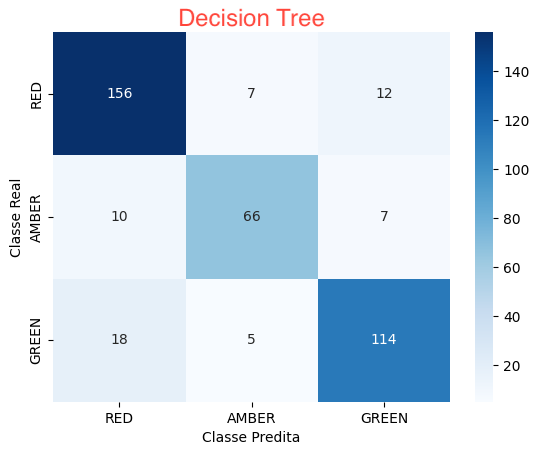
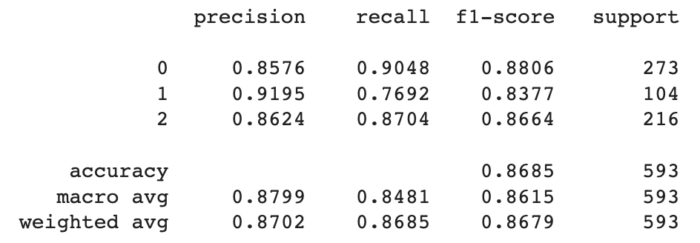
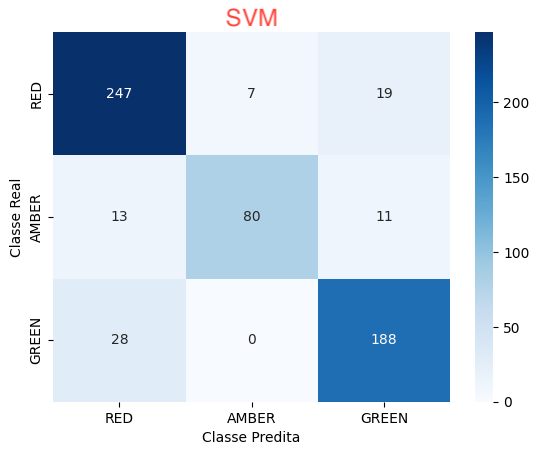
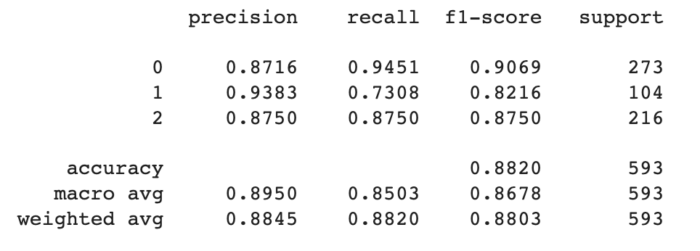
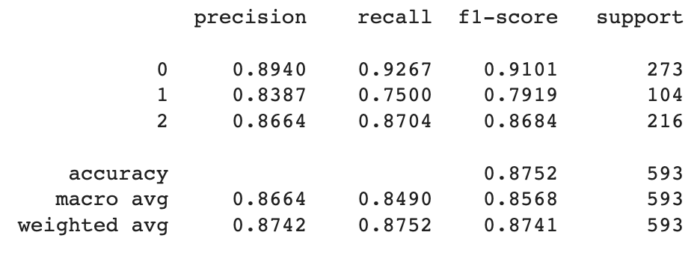
Para cada abordagens incluímos as métricas de Precisão, Recall, F1-Score e Suporte, além do resultado da Matriz de Confusão.
Naive Bayes
Algoritmo de classificação baseado no Teorema de Bayes, que assume independência condicional entre os atributos. É especialmente útil para classificação de texto e problemas de linguagem natural.
Decision Tree
(Árvore de Decisão): Algoritmo de aprendizado supervisionado que cria uma estrutura de árvore de decisão para dividir o conjunto de dados em segmentos mais homogêneos, tomando decisões com base em regras condicionais nos atributos.
SVM
(Support Vector Machine): Algoritmo de aprendizado de máquina que busca encontrar o hiperplano que melhor separa as classes de dados, maximizando a margem entre elas. É útil para problemas de classificação binária e também pode ser estendido para classificação multi-classe.
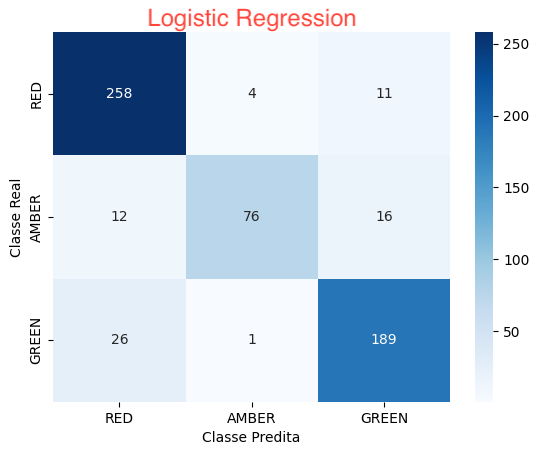
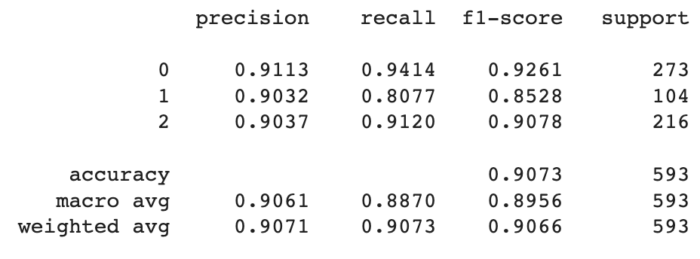
Logistic Regression
(Regressão Logística): Algoritmo de aprendizado supervisionado usado para problemas de classificação binária. Ele modela a probabilidade de uma instância pertencer a uma determinada classe usando uma função logística.
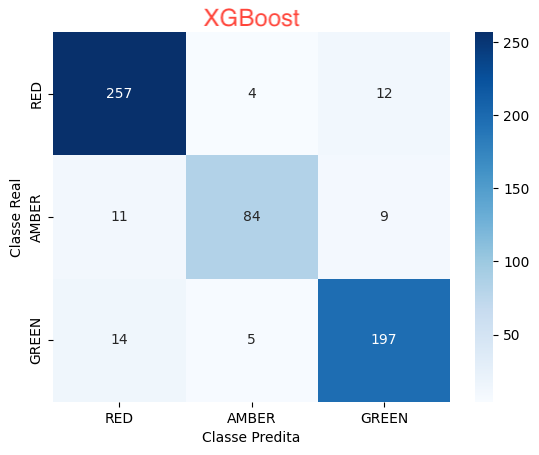
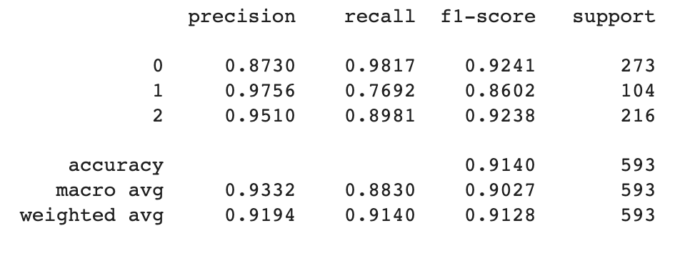
XGBoost
Implementação eficiente e escalável de árvores de decisão usando gradient boosting. É amplamente utilizado para problemas de classificação e regressão, e tem se destacado em competições de ciência de dados.
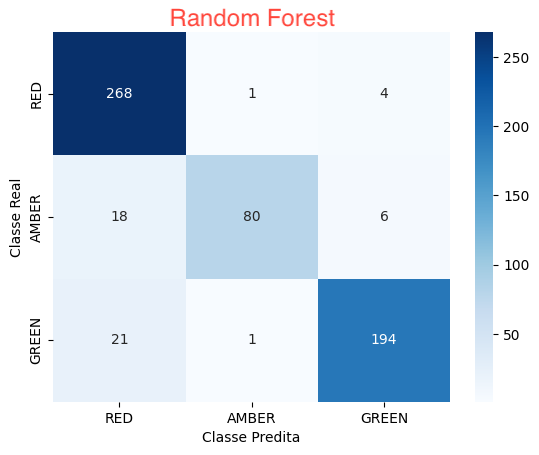
Random Forest
(Floresta Aleatória): Algoritmo de aprendizado de conjunto (ensemble learning) baseado em árvores de decisão. Ele cria várias árvores de decisão aleatórias e combina suas previsões para melhorar a precisão e reduzir o overfitting.
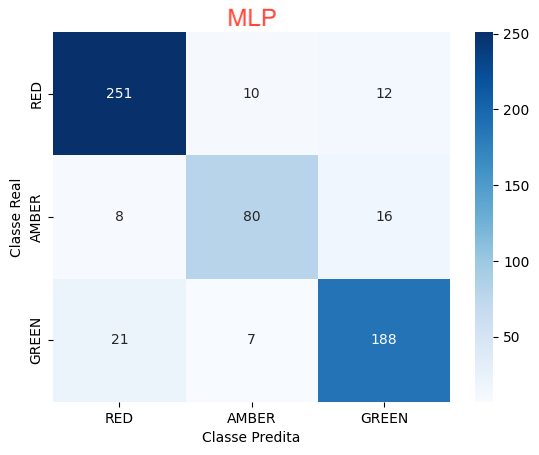
MLP Classifier
O MLPClassifier é uma classificador de Perceptron de múltiplas camadas. Ao contrário de outros algoritmos de classificação, como SVM ou o Naive Bayes, o MLPClassifier se baseia em uma Rede Neural para realizar a tarefa de classificação.
A rede neural artificial do MLPClassifier é composta por várias camadas de neurônios, incluindo uma camada de entrada, uma ou mais camadas intermediárias (também chamadas de camadas ocultas) e uma camada de saída. Cada neurônio em uma camada está conectado a todos os neurônios na camada seguinte por meio de pesos ajustáveis.
O processo de treinamento de um MLPClassifier envolve a passagem dos dados de treinamento pela rede, ajustando os pesos das conexões entre os neurônios para minimizar o erro entre as saídas previstas pela rede e as saídas reais esperadas. Isso geralmente é feito usando algoritmos de otimização, como o algoritmo de retropropagação (backpropagation).
Comparativo entre abordagens
Nesta seção trabalhamos os resultados das abordagens de classificação previamente citadas sobre a base de dados escolhida.
- A abordagem que melhor identificou a classe RED foi a Random Forest: 268 ocorrências
- A abordagem que melhor identificou a classe AMBAR foi a XGBoost: 84 ocorrências
- A abordagem que melhor identificou a classe GREEN foi a XGBoost: 197 ocorrências
- A abordagem que mais identificou falsos positivos na classe RED foi a SVM: 41 ocorrências
- A abordagem que mais identificou falsos positivos na classe AMBAR foi a Naive Bayes: 23 ocorrências
- A abordagem que mais identificou falsos positivos na classe GREEN foi a SVM: 30 ocorrências
- A abordagem que mais identificou falsos negativos na classe RED foi a SVM: 26 ocorrências
- A abordagem que mais identificou negativos positivos na classe AMBAR foi a Logistic Regression: 28 ocorrências
- As abordagens que mais indetificaram falsos negativos na classe GREEN foram a SVM e a MLP: 28 ocorrências
Desenvolvendo o Modelo de Classificação com Aprendizado de Máquina
Nesta seção do trabalho propomos a utilização de redes neurais LSTM para realizar a classificação das mensagens de projeto com o status RAG. O desenvolvimento do Modelo de Classificação é um processo que envolve etapas importantes, onde decisões de implementação são fundamentais para alcançar resultados mais eficazes e aprimorar a precisão da classificação. Nas subseções abaixo, seguiremos o fluxo padrão de trabalho para resolver problemas de machine learning.
Coleta de dados
A base de dados é estruturada de forma simples, sendo cada amostra constituída por uma coluna com série de palavras sobre a situação da tarefa, uma coluna indicando a classificação da situação (RED, Amber, Green) e uma coluna de apoio para separação entre base de treinamento e base de validação.
A base foi composta por duas fontes distintas. Primeiramente, realizamos a tradução para português dos dados utilizados pela Oracle no artigo previamente citado. Na sequência, alimentamos a base com comentários de tarefas e classificações manuais realizados no software NetProject.
Análise dos Dados
Após carregar o dataframe com o Pandas, o próximo passo é percorrer os textos e analisá-los em tokens individuais, representando cada palavra com um número inteiro para simplificar o processamento.
Esses tokens numéricos também serão utilizados como índices de coluna em uma matriz de contagem de ocorrências, conhecida como matriz de termo do documento.
Essa etapa de numeração também criará o vocabulário do corpus, que será uma lista ordenada de palavras com base em sua frequência de ocorrência em todo o conjunto de dados. Geralmente, palavras com frequência inferior a um valor mínimo, como 3 ou 2, serão excluídas do vocabulário.
Escolha do Modelo e Preparação dos dados
O calculo da proporção entre o número de amostras e o número de palavras por amostra foi menor que 1500. Nesse cenário o ideal é tokeniza o texto em n-grams e utilizar um modelo simples de perceptron de múltiplas camadas (MLP) para classificação
Optamos pelo uso de aprendizado de transferência em nosso modelo. Com origem na modelagem de reconhecimento de imagem, o aprendizado de transferência aproveita modelos pré-treinados (geralmente grandes) e adiciona ou ajusta as camadas finais para classificação específica. A NLP clássica, antes do advento das redes neurais profundas e do aprendizado por transferência, envolvia tokenização e análise estatística de ocorrências de palavras.
O aprendizado por transferência indutiva teve um grande impacto na visão computacional, mas as abordagens existentes em PNL ainda exigem modificações específicas de tarefas e treinamento desde o início. Propomos o Ajuste Fino do Modelo de Linguagem Universal (ULMFiT), um método eficaz de aprendizagem por transferência que pode ser aplicado a qualquer tarefa em PNL, e introduzimos técnicas que são essenciais para o ajuste fino de um modelo de linguagem. \cite{howard2018universal}
O tokenizador padrão no fastai é parte da biblioteca spaCy, já citado previamente neste artigo e que também será utilizado no desenvolvimento do Modelo de Classificação com Aprendizado de Máquina.
A Biblioteca Fast AI
A biblioteca fastai é uma biblioteca de código aberto de aprendizado profundo (deep learning) desenvolvida com o objetivo de tornar o processo de desenvolvimento de modelos de aprendizado de máquina mais acessível e eficiente. Ela foi criada com base na biblioteca PyTorch, outra popular biblioteca de aprendizado de máquina.
A fastai fornece uma interface de alto nível que simplifica a criação e treinamento de modelos de aprendizado profundo, permitindo que os desenvolvedores e cientistas de dados construam e treinem modelos poderosos com menos código e esforço. A biblioteca foi projetada para ser amigável para iniciantes, enquanto ainda oferece flexibilidade para usuários avançados.
A biblioteca oferece suporte para transferência de aprendizado (transfer learning), que permite aproveitar modelos pré-treinados em grandes conjuntos de dados para tarefas específicas. Facilita o treinamento de modelos com técnicas avançadas, como aprendizado por curriculum e discriminative learning rates. Implementa algoritmos modernos de aprendizado de máquina com métodos atualizados e inovadores. Oferece suporte para tarefas específicas, como processamento de linguagem natural (NLP) e visão computacional.
Criação e treinamento do modelo
Nessa etapa do trabalho utilizamos a função TextDataLoaders from df da biblioteca fastai, para criar um conjunto de dados pronto para treinamento de modelos de Aprendizado Profundo (Deep Learning) a partir de um DataFrame do pandas contendo as amostras textuais de nossa base. A função permite que a criação conjuntos de dados prontos para treinamento de modelos de linguagem ou modelos de classificação de texto de maneira rápida e fácil. Ela realiza automaticamente o pré-processamento do texto, tokenização, criação de vocabulário, criação de batches e outras tarefas relacionadas ao processamento de texto para o treinamento eficiente do modelo.
Para treinar o classificador, usaremos uma técnica chamada descongelamento gradual. Podemos começar treinando as últimas camadas, depois retroceder e descongelar e treinar as camadas anteriores. Podemos usar a função do aprendiz (learner) learn.freeze-to(-2) para descongelar as duas últimas camadas.
Também usamos a função learn.recorder.plot-losses() para acompanhar nossa função de perda ao longo das épocas.
Avaliação do Modelo
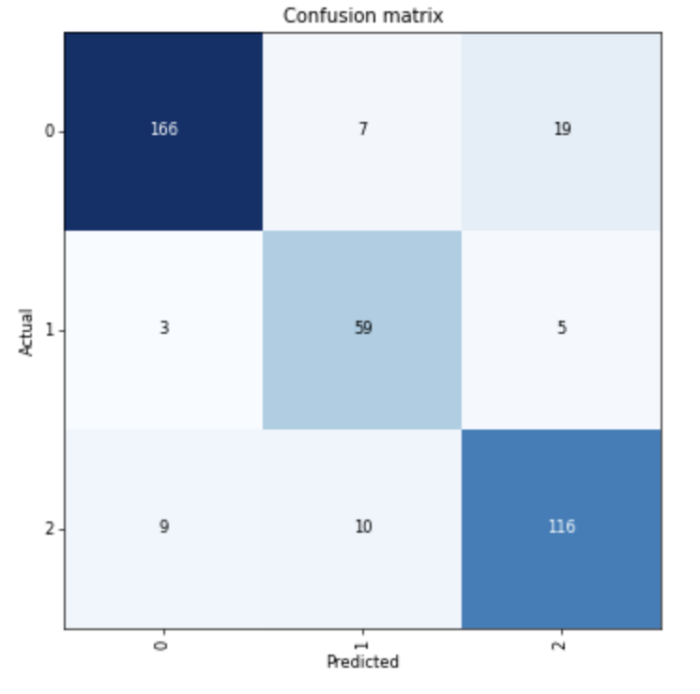
A imagem abaixo apresenta a Matriz de confusão do Modelo de Classificação utilizando Aprendizado de Máquina. Em 166 amostras a classe GREEN foi predita corretamente. Em 59 amostras a classe RED foi predida corretamente. Em 116 amostras a classe AMBER foi predita corretamente.
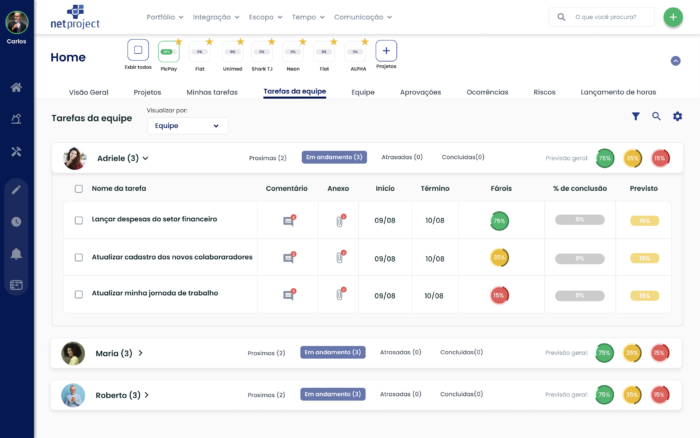
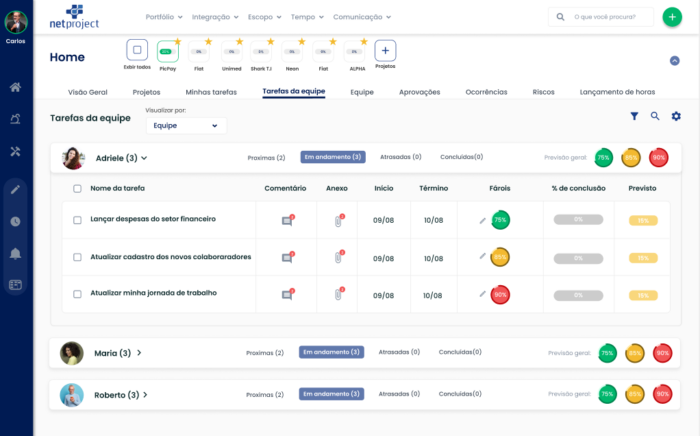
Aplicação dos Modelos no Software NetProject
Os modelos previamente treinados serão implantados para uso no software NetProject. A imagem abaixo apresenta a tela de trabalho inicial de um usuário da ferramenta. A coluna Faróis representa o status RAG da tarefa em questão. Por exemplo, a tarefa Lançar Despesas do setor financeiro apresenta uma predição de status Green com acurácia de 75 % na previsão.
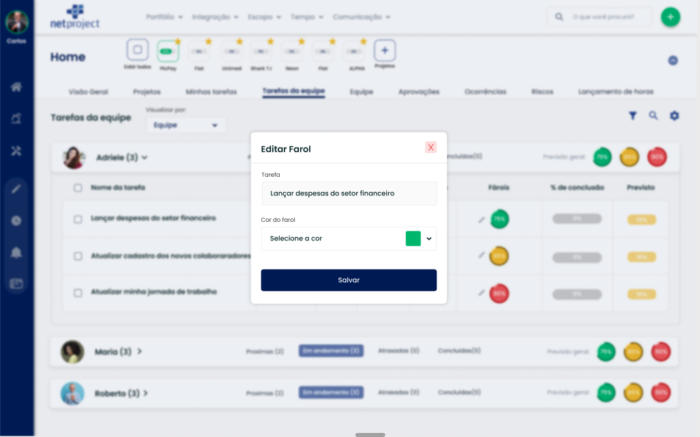
A imagem abaixo apresenta uma iteração do usuário com o sistema em que o usuário deseja modificar ou confirmar um status predito. Será possível, por exemplo, confirmar o status Green predito ou alterar para um novo Status. O status que o usuário definir ficará ativo até a próxima atualização de predição, com base nos novos comentários que forem adicionados a tarefa.
Conclusão e Trabalhos Futuros
Este trabalho propôs o desenvolvimento de um modelo de aprendizado de máquina, com apoio de NLP e Redes Neurais, para priorizar tarefas através de algoritmos de classificação de nível de riscos de acordo com marcadores RAG.
O Modelo de Classificação utilizando aprendizado de máquina foi realizado com transferência de aprendizado sobre um modelo que não foi pré-treinado com um corpus da linguagem portugesa. Entendemos que o modelo possa ser pré-treinado com um conjunto de informações provenientes de grandes sistemas de acompanhamento de projetos e seus consequentes problemas que sejam públicos, como o o StackOverflow ou o próprio GitHub. Os rótulos RED poderiam ser atribuídos a comentários que não fossem de conclusão do problema relatado. Os rótulos GREEN poderiam ser atribuídos a comentários de conclusão do problema.
Outra possibilidade de trabalho futuro seria a inclusão da perspectiva de análise de sentimento aos comentários de tarefas, explorando mais os trabalhos propostos por Bing Liu. Nesse trabalho, os autores fornecem uma investigação abrangente sobre as capacidades de Modelos de Linguagem com Aprendizado de Linguagem (LLMs) na realização de várias tarefas de análise de sentimentos, desde a classificação convencional de sentimentos até a análise de sentimentos baseada em aspectos e análise multifacetada de textos subjetivos.