

Tempo de leitura: 10 minutos
Mais um artigo da série em que trabalhamos o uso de Inteligência Artificial na Gestão de Projetos.
Aqui na NetProject, entendemos que o tempo de trabalho do gerente de projetos é de suma importância para a organização e deve ser sempre melhor aproveitado. Ao liberar o gerente de atividades repetitivas e rotineiras, permitimos que ele execute as responsabilidades essenciais de planejamento, coordenação, comunicação, gerenciamento de riscos e controle.
Um gerente de projetos bem-sucedido precisa de tempo adequado para realizar essas atividades de maneira eficaz e garantir o sucesso do projeto.
Assim, qualquer mecanismo que execute tarefas repetitivas automaticamente está sendo por nós avaliado.
Um deles é o Classificador Automático em Formulários de Projeto.
Os Formulários de Projeto.
Imagino que esteja se perguntando, o quê são formulários de projeto? Certamente você já se deparou com alguns deles:
Business Case ou Pré-Projeto: Um Business Case, também conhecido como Caso de Negócio, é um documento que justifica a viabilidade de um projeto, iniciativa ou investimento em termos financeiros e estratégicos. Ele é usado para tomar decisões informadas sobre a alocação de recursos e determinar se um projeto ou investimento é justificável do ponto de vista econômico. O Business Case descreve os benefícios esperados, os custos associados, os riscos envolvidos e as alternativas consideradas. Ele fornece uma análise detalhada dos aspectos financeiros, comerciais e estratégicos relevantes, ajudando a avaliar se o projeto atenderá às necessidades da organização e se é uma escolha sensata
Termo de Abertura do Projeto: O Termo de Abertura do Projeto (TAP), também conhecido como Project Charter em inglês, é um documento formal que marca o início de um projeto. Ele é criado pelo gerente de projetos ou pelo patrocinador do projeto e serve como uma autorização oficial para iniciar o trabalho. O TAP é geralmente desenvolvido durante a fase de iniciação do projeto e é usado como referência ao longo de todo o ciclo de vida do projeto.
Declaração de Escopo do Projeto: Uma declaração de escopo, também conhecida como Declaração de Escopo do Projeto, é um documento que define de forma clara e concisa os limites, objetivos, entregas e requisitos de um projeto. É uma parte essencial do processo de planejamento do projeto e estabelece a base para o trabalho a ser realizado. A declaração de escopo descreve o que está incluído e o que está excluído do projeto, definindo as fronteiras do trabalho a ser executado. Ela fornece uma visão geral do projeto, alinhando as expectativas de todas as partes interessadas e fornecendo orientação para a equipe do projeto.
Ficha de Riscos: Uma Ficha de Riscos também conhecida como Registro de Riscos ou Formulário de Identificação de Riscos, é um documento utilizado para registrar e documentar os riscos identificados em um projeto, organização ou atividade específica. É uma ferramenta fundamental no gerenciamento de riscos, pois ajuda a identificar, analisar e monitorar os riscos ao longo do ciclo de vida do projeto ou atividade.
Termo de Encerramento do Projeto: O Termo de Encerramento do Projeto, também conhecido como Encerramento do Projeto ou Termo de Encerramento, é um documento que formaliza o encerramento de um projeto. Ele é elaborado no final do ciclo de vida do projeto, após a conclusão de todas as atividades e entregas planejadas. O Termo de Encerramento do Projeto é importante porque fornece uma revisão geral do projeto, resume os resultados alcançados, avalia o desempenho e registra lições aprendidas. Ele também comunica o encerramento do projeto para as partes interessadas relevantes, encerra as obrigações contratuais e libera recursos para outras iniciativas.
Todos estes formulários possuem campos de seleção, ou combos, que vamos passar a chamar daqui pra frente de classificações. Por exemplo, Tipo de Projeto, Categoria de Projeto, Tipo de Risco, Tipo de Tarefa, dentre outros.
Como podemos poupar tempo do gerente para preencher estas classificações?
Processamento de Linguagem Natural
O Processamento de Linguagem Natural, do inglês Natural Language Processing (NLP) é um campo da inteligência artificial (IA) que se concentra na interação entre computadores e linguagem humana. Ele envolve o desenvolvimento e aplicação de técnicas computacionais para entender, interpretar, manipular e gerar linguagem humana de forma natural.
O objetivo do processamento de linguagem natural é capacitar os computadores a entender e processar a linguagem humana em diferentes formas, como texto escrito, áudio e fala.
Representação textual
Para que um computador possa entender e processar um texto, é necessário representar esse texto em uma forma que possa ser compreendida pelos algoritmos e modelos de processamento de linguagem natural. Existem várias técnicas de representação de texto que são comumente utilizadas. Alguns exemplos:
- Bag-of-Words (saco de palavras): Essa abordagem simplificada considera um texto como uma coleção de palavras, ignorando a ordem e a estrutura gramatical. Cada documento é representado como um vetor contendo a frequência ou presença das palavras encontradas nele. É uma técnica simples, mas perde informações importantes sobre a sequência das palavras.
- Count Vectorizer: O CountVectorizer é uma técnica de vetorização de texto utilizada para representar textos como vetores numéricos. É uma etapa comum de pré-processamento em tarefas de processamento de linguagem natural, como classificação de texto e análise de sentimentos. O CountVectorizer converte um conjunto de documentos de texto em uma matriz de contagem de termos. Cada documento é tratado como uma “bag-of-words” (saco de palavras), onde a ordem das palavras é ignorada e apenas a frequência de ocorrência de cada palavra é considerada.
- TF-IDF (Term Frequency-Inverse Document Frequency): Essa técnica pondera as palavras com base na frequência em um documento específico (term frequency) e na frequência inversa em todo o corpus (inverse document frequency). Isso ajuda a destacar palavras mais importantes em relação ao documento específico e ao corpus em geral.
- Representação vetorial (embedding): Essa técnica mapeia palavras ou frases em vetores numéricos de alta dimensionalidade. Um exemplo popular é o Word2Vec, que mapeia palavras em vetores densos com base em sua distribuição em um corpus de texto. Isso permite que as palavras sejam representadas numericamente e captura relações semânticas e sintáticas entre elas.
- Modelos de linguagem pré-treinados: Esses modelos são treinados em grandes quantidades de texto para aprender padrões linguísticos e representações de palavras. Exemplos populares são o GPT (Generative Pre-trained Transformer) e o BERT (Bidirectional Encoder Representations from Transformers). Esses modelos podem ser usados para extrair representações contextuais de palavras e até mesmo de frases ou documentos inteiros.
Classificação em NLP
A tarefa de classificação em Processamento de linguagem Natural (NLP) refere-se ao processo de atribuir uma categoria ou rótulo a um texto com base em seu conteúdo.
É uma das tarefas fundamentais no campo do NLP e possui uma ampla gama de aplicações.
Na classificação de texto, um algoritmo ou modelo é treinado para aprender a associar automaticamente textos a uma ou mais categorias pré-definidas. Essas categorias podem ser sentimentos (positivo, negativo, neutro), tópicos (esportes, política, tecnologia), intenções (perguntas, afirmações, solicitações) ou qualquer outra classe específica que seja relevante para o contexto do problema.
A classificação em NLP geralmente segue os seguintes passos:
- Conjunto de treinamento: Um conjunto de textos é coletado e rotulado manualmente com suas respectivas categorias. Esses textos são usados para treinar o modelo de classificação.
- Pré-processamento: Os textos passam por uma etapa de pré-processamento, que inclui remoção de pontuação, conversão para letras minúsculas, tokenização (divisão em palavras ou outros tokens) e aplicação de técnicas de normalização, como lematização ou stemming.
- Vetorização: Os textos são convertidos em representações numéricas. Técnicas como CountVectorizer, TF-IDF ou modelos de linguagem pré-treinados (como o Word2Vec ou o BERT) podem ser usados para criar vetores numéricos a partir dos textos.
- Treinamento do modelo: Um modelo de classificação é selecionado e treinado com o conjunto de treinamento, utilizando os vetores numéricos e suas respectivas categorias. Algoritmos populares para classificação de texto incluem Naive Bayes, Support Vector Machines (SVM), árvores de decisão e redes neurais.
- Avaliação do modelo: O modelo treinado é avaliado usando um conjunto de teste, que contém textos não vistos durante o treinamento. Métricas de desempenho, como precisão, recall, F1-score e acurácia, são utilizadas para medir o quão bem o modelo está classificando os textos em relação às categorias esperadas.
- Predição: Após o treinamento e avaliação, o modelo é usado para prever a categoria de novos textos não rotulados. O texto é pré-processado da mesma forma que o conjunto de treinamento e vetorizado antes de ser submetido ao modelo para classificação.
Classificação Automática em Formulários de Projeto
Todo sistema PPM, ou Portfólio Project Management, armazena uma grande quantidade de informações que vão muito além do cronograma do projeto. Todos os formulários que citamos acima devem estar presentes em uma base de dados integrada e organizada, que permita o trabalho e a recuperação de qualquer informação do projeto.
Nosso objetivo é usar as informações que foram previamente alimentadas nos projetos já executados pela organização para alimentar os Classificadores e então sugerir ao Gerente do Projeto a opção mais adequada para o novo preenchimento de formulário que está sendo realizado.
Sendo direto, vamos usar, por exemplo, as tarefas previamente cadastradas e suas classificações de tipo, juntamente com o nome da tarefa e qualquer outro campo descritivo que a mesma possua para:
Conjunto de treinamento: Alimentar um conjunto de treinamento com as informações já cadastradas, que identificam qual o tipo de tarefa a empresa definiu para as tarefas já criadas.
Pré-processamento: Aplicar as técnicas de pré-processamento acima citadas
Vetorização: Converter os textos em representações numéricas, provavelmente usando modelos de linguagem pré-treinados (como o Word2Vec ou o BERT).
Treinamento do modelo: Avaliar qual o melhor algoritmo para classificação de text, dentre Naive Bayes, Support Vector Machines (SVM), árvores de decisão e redes neurais.
Avaliação do modelo: Avaliar o modelo treinado com apoio conjunto de teste
Predição: Incluir a predição na interface do software NetProject. Com o seguinte formato:
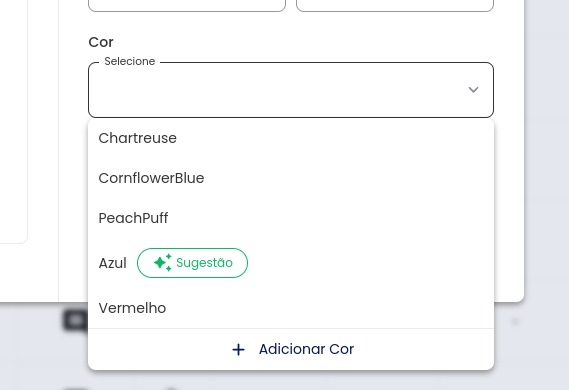
Vale ressaltar que o ciclo que vai desde o estabelecimento do conjunto de treinamento até a construção do modelo precisam ser realizados periodicamente, estamos incluíndo na interface do software NetProject a execução deste ciclo de forma agendada, para que seja feito um refinamento progressivo dos classificadores.
Entre em contato conosco para conhecer mais!

